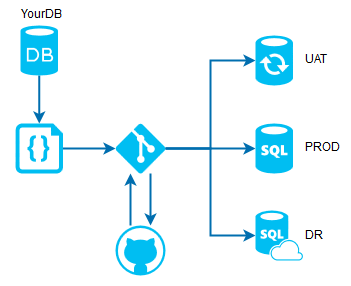
 |
| You can maintain and deploy code easily |
Source control is a vital part of IT work, since it is used to track changes over software and documents, with two main benefits: having a centralized, up to date copy of all your applications and utilities, and to be able to rollback to a previous stable version in case of a failed deployment.
This is perfectly applicable to SQL Server, where you want to have an updated and ready to deploy elsewhere copy of your database objects.
There are a lot of source control applications and software, everyone has its pros and cons, but personally, I like to use
GitHub, since it is free to use and since it was recently acquired by Microsoft, support for other products is easier (SQL Server for this case).
On this post, I will show you how to implement a source control for a database using GitHub and
Azure Data Studio (ADS).
Setting up your machine
First of all, you need to have Azure Data Studio installed and running on your machine, and also a GitHub account to be able to upload and maintain your files.
You will need
Git to be able to use source control features in ADS, you can download from
here. After downloading it, proceed to install it on your local machine (default features are ok).
To verify Git is installed correctly, just open any command prompt and type
git then press enter:
Configuring Azure Data Studio
To be able to use source control on ADS, we have to perform some simple steps:
Open ADS and click on File>Open Folder, locate the folder you want for work and click OK (can be an empty folder for now).
For this example, I am using
C:\Repos\SourceControlDB
You can see that now the selected folder appears on the top bar
Once a folder is selected, click on Source Control, located on the left bar
Click on Initialize Repository
And that is all, you are ready to work with source control.
Working with Git
Adding a file to source control
Now we will add an object to our Git folder to see how sourcing works.
Open any already created database object or a TSQL query on ADS IDE
Save it on your Git Folder with a meaningful name
Once saved, you can see the file is added to the source control as an untracked change
Just select the changes you want to commit (in case you have more open files) and then click on Commit on the upper right corner of the source control area
Since the changes have not been staged, a message box asking to do it automatically, click on Yes
Provide a meaningful commit message and press Enter
Now the file has been added to source control successfully.
Editing the file
We now proceed to do a simple change in the stored procedure
At the moment you save the file, you can notice that a new change is added to source control and modified or added lines are marked on the file
If you click on the change, you can now see the actual changes made to the file
If you are Ok with the changes, commit them using the same option as earlier, and that is the basic Git usage.
We will cover the rollback, merge and some other features on the next post.
Now we will learn how to upload your local Git files to GitHub.
Linking your repository to GitHub the first time
The easiest way is using your GitHub profile, so let's do it...
Create a new repository on your profile with the options you want, and click on Create Repository
In the next step copy the code for pushing an existing Git repository
Open a new command prompt, navigate to your Git folder and paste the code there, one line at a time
In my case for the first line, the origin already exists so it will throw an error, but for your first time it will execute ok, for the second line, after a few moments it will ask you for username and password
After a few moments (depending on your folder size) files will be uploaded and now your repository is uploaded to GitHub successfully (as long with all the versions you have)
You have successfully linked your Git folder with GitHub, as you can see the file is uploaded
Your GitHub is now linked
Since we have done the linking, you can upgrade existing or add new files and they will be uploaded to GitHub when you commit the changes and sync them.
We perform another quick change to our file and commit it
Then we click on Sync to synchronize with GitHub
After the process ends, if you check your GitHub repository you can see the new change
Now you have configured your environment to support source control directly to GitHub. On the next post, we will see some other advanced options, like perform the sync automatically.
Also, we will learn how to pull those files from another place and apply them to other SQL Server instance.